This article is a summary of the StatQuest video made by Josh Starmer. Click here to see the video on Ridge Regression explained by Josh Starmer. Click here to see the video on Lasso Regression explained by Josh Starmer.
Overfitting In statistics, overfitting is the production of an analysis that corresponds too closely or exactly to a particular set of data, and may therefore fail to fit additional data or predict future observations reliably. An overfitted model is a statistical model that contains more parameters than can be justified by the data. Overfitting is the use of models or procedures that violate Occam’s razor, for example by including more adjustable parameters than are ultimately optimal, or by using a more complicated approach than is ultimately optimal. The most obvious consequence of overfitting is poor performance on the validation dataset.
Bias-Variance Tradeoff In statistics and machine learning, the bias–variance tradeoff is the property of a set of predictive models whereby models with a lower bias in parameter estimation have a higher variance of the parameter estimates across samples, and vice versa. Ideally, we would know the exact mathematical formula that describes the relationship between two variables (e.g. height and weight of the mice).
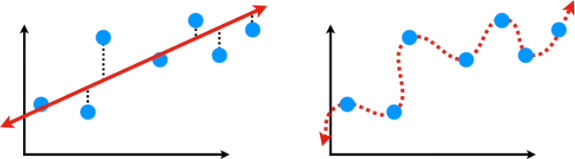
To do that, we use the machine learning to approximate the formula. Then, we split the data in train and test. Image now the first machine learning model is a Linear Regression, but is not accurate to replicate the curve of the true relationship between height and weight. The inability for a machine learning to capture the true relationship is called Bias. Another machine learning model might fit a Squiggly Line to the training set, which is super-flexible to fit the training-set. But, when we calculate the Sum of the Squared Error in the Test-set, we probably find that the Linear Line is better than the Squiggly Line, and we call this Overfitting. In Machine Learning Lingo, the difference in fitting between Training and Testing is called Variance. In Machine Learning the ideal algorithm need to have Low Bias and has to be able to accurately approximate the true relationship. Two commonly used methods to find the best between Simple and Complicated are: Regularization L1 and L2.
L2 Ridge Regression It is a Regularization Method to reduce Overfitting. We try to use a trend line that overfit the training data, and so, it has much higher variance then the OLS. The main idea of Ridge Regression is to fit a new line that doesn’t fit the training data. In other words, we introduce a certain Amount on Bias into the new trend line.
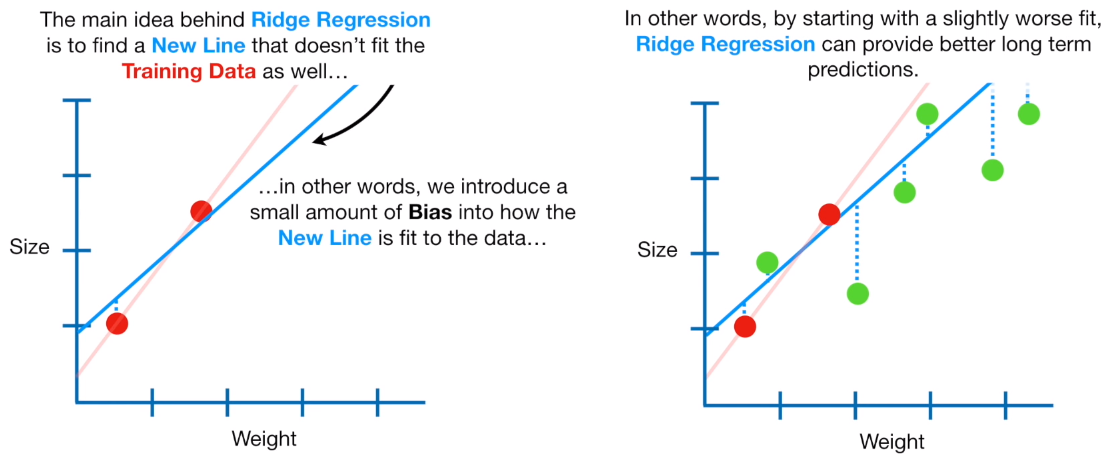
What we do in practice, is to introduce a Bias that we call Lambda, and the Penalty Function is: lambda*slope^2. The Lambda is a penalty terms and this value is called Ridge Regression or L2.
The L2 penalty is quadratic: lambdaslope^2: none of the coefficients (slope) are extremely large. The L1 penalty is the absolute value: lambda|slope|: choose the most important features.
When Lambda = 0, the penalty is also 0, and so we are just minimizing the sum of the squared residuals. When Lambda asymptotically increase, we arrive to a slope close to 0: so, the larger LAMBDA is, our prediction became less sensitive to the independent variable. We can use Cross-Validation, typically 10-Fold Cross Validation is used in order to determine which LAMBDA give back the lowest VARIANCE. Lambda is the Tuning Parameter that controls the bias-variance tradeoff and we estimate its best value via cross-validation.
L1 Lasso Regression It is a Regularization Method to reduce Overfitting. It is similar to RIDGE REGRESSION except to a very important difference: the Penalty Function now is: lambda*|slope|.
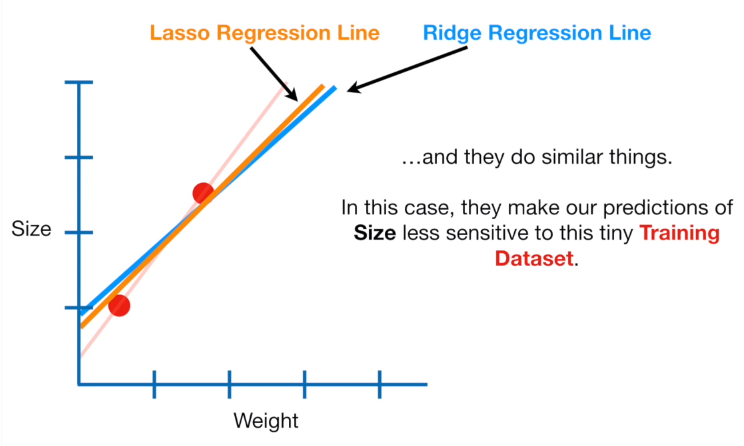
The result of the Lasso Regression is very similar to the Result given by the Ridge Regression. Both can be used in Logistic Regression, Regression with discrete values and Regression with interaction. The big difference between Rdge and Lassp start to be clear when we Increase the value on Lambda. In fact, Ridge can only shrink the slope asynmtotically close to zero, while Lasso can shrink the slope all the way to zero. The advantage of this is clear when we have lots of parameters in the model. In Ridge, when we increase the value of Lambda, the most important parameters might shrink a little bit and the less important parameter stay at high value. In contrast, with Lasso when we increase the value of Lambda the most important parameters shrink a little bit and the less important parameters goes closed to zero. So, Lasso is able to exclude silly parameters from the model.