We want to differentiate between spam (called spam) and non-spam (called ham) email based on the content. We use a training set of textual data that are already labeled spam/non-spam email.
We start removing empy columns, and we call our columns label and text. We also create a corpus, remove punctuation, transform everything into lowercase, remove numbers, and stop words. Then, we have to stamming the document, and finally we have a corpus of terms. with out sparse terms. Finally, we can convert the corpus into a data frame, and add the dependent variable label. Now, we can split the data between Training and Test set.
library(caTools)
library(e1071)
library(rpart)
library(rpart.plot)
library(wordcloud)
library(tm)
library(SnowballC)
library(ROCR)
library(RColorBrewer)
library(stringr)
# Remove empty columns
spam$X = NULL
spam$X.1 <- NULL
spam$X.2 <- NULL
names(spam) <- c("label","text")
levels(as.factor(spam$label))[1] "ham" "spam"# Clean the text
corpus <- Corpus(VectorSource(spam$text))
corpus <- tm_map(corpus, removePunctuation)
corpus <- tm_map(corpus, content_transformer(tolower))
corpus <- tm_map(corpus, removeNumbers)
corpus <- tm_map(corpus, stripWhitespace)
corpus <- tm_map(corpus, removeWords, stopwords('english'))
corpus <- tm_map(corpus, stemDocument)
# Obtain document term matrix
myDtm <- DocumentTermMatrix(corpus)
# findFreqTerms(myDtm, lowfreq=100)
sparse = removeSparseTerms(myDtm, 0.995) # remove words not appear 99.5% of the time
# Convert to a data frame
emailSparse = as.data.frame(as.matrix(sparse))
emailSparse$label=spam$label
# Add dependent variable
library(caTools)
set.seed(123)
n = nrow(emailSparse)
idx <- sample(n, n * .75) # split data to testing and train set
train = emailSparse[idx,]
test = emailSparse[-idx,]Now, we can create a Recursive Partitioning And Regression Trees Model. This is a statistical method for Multivariable Analysis that is able to create a Decision Tree that try to classify terms by splitting it by dichotomous dependent variable, in this case label=ham (non-spam), label=spam. The method is called Recursive because each subpopulation may be splitted many number of times until a specific criteria is reached. The Advantages of Recursive Partitioning is that is an intuitive model which does not require a lot of calculations. The Disadvantage is that it can not work well with continuous variable because it may overfit data.
library(rpart)
library(rpart.plot)
# Recursive Partitioning And Regression Trees Model
emailCART = rpart(label ~ ., data=train, method="class")
# summary(emailCART)
prp(emailCART) # plot the tree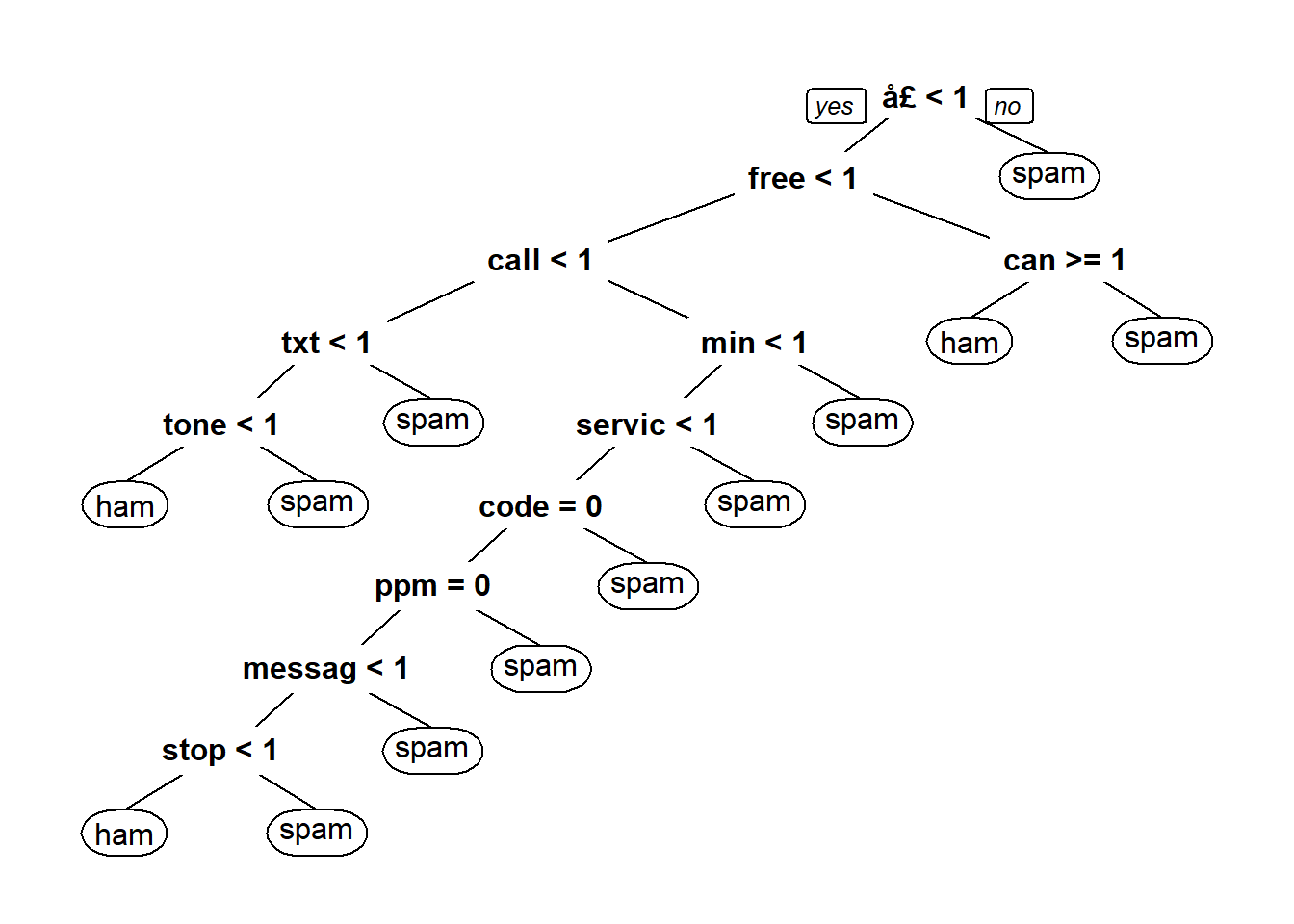
As we can see from the graph above, if the word call is less than 0.5 of probability and claim or mobil is less than 0.5, the email is a spam.
# Evaluate the performance of the model
predictCART = predict(emailCART, newdata=test, type="class")
table(test$label, predictCART) predictCART
ham spam
ham 1180 26
spam 60 127# Overall accuracy
(1180+127)/(1180+127+60+26)[1] 0.9382627The results above show the Confusion Matrix and the relative Accuracy (93%). Based on a very simple Decision Trees Model we can identify email with a 93% of Accuracy. We are also able thanks to the graph above to see which predictors had an important role to identify if the email was spam or not.